The 7 Rules for Writing Software That Won’t Die When You Do
Your software is your legacy. It is up to you to decide how long that legacy lives for.
Life ends. But software doesn’t have to.
After the wild success of “joe” (and the blog post that followed), I posted a tweetstorm listing some of the rules that I think separate good software from bad software. A few people got in touch with me after that to talk shop and asking for clarification on some of them.
Let me be perfectly clear, though. It is only rarely possible to follow all of these rules for any given project. I myself am guilty of not following all of them successfully. But the more rules you follow (read: preach), the longer your software will live. At the end of the day, every byte you write adds to the whole ecosystem, and as engineers, our goal should be to keep the software ecosystem as clean as possible.
Fast
But what do you get out of writing good code? Isn’t “move fast break things” a good thing?
No. Learning to make software is a skill. Anyone can do it. Learning to make good software is an art. It requires time, effort and dedication.
When you die, do you want the world to have more SEGFAULTs than it already does? Do you want the sysadmins to constantly be on call because of the shitty code you wrote that breaks everything? Do you want your PM to remember you as being the engineer who pissed all users off?
I have nothing against moving fast — I do believe in the power of MVP’s and the power of getting out first. But at some point, when it’s not too late, you do have to realize that low quality code can only go so far.
When
When you walk into a doctor’s office, the doctor first asks you a series of questions to determine what is up with you. They don’t prescribe drugs before diagnosis.
Similarly, it is important to know when you are writing bad software. Here’s a few questions that will help us diagnose if you are writing bad software.
-
Does pushing updates to the software take a lot of time and effort?
-
Does the whole system go down when you push a very small change?
-
Have you ever pushed broken code to production, and didn’t realize until your users started complaining?
-
Do you know what exactly to do when your system goes down — how to dig into backups, and deploy them?
-
Are you spending more time on things like moving between environments, or running the same commands again and again, or running small utilities than actually making the software?
If you answered yes to any of these questions, this post is for you. Read all the way through, at least twice.
So let’s see what those rules are, shall we?
1. Modularize
Rule 1: Modularize. Pushing 1 module with a bug in it is significantly less work that pushing the whole codebase.
— Karan Goel (@karangoel) January 16, 2015We humans are extremely complex creatures with the most sophisticated CPU ever designed. Yet, it fails to solve complex problems. Want proof? Tell me, without using any calculators, what 13*35 is. I bet you can’t. At least not in a reasonable amount of time.
BUT. What we are good at is decomposing complex problems into smaller and solvable problems.
What is 13*10? 130. What is 13*5? It’s 130/2 = 65. What is 130*3? 390. What is 390+65? 455. BAM!
See how breaking a large problem down to small, independent and easy problems helped us get to the right answer?
Follow the same logic for your software. Divide up your software across multiple files, or folders, or even projects. Bring all dependencies in one location, follow MVC or some variation.
Not only will this code be fun to read, it will also be so much easier to debug. In most cases, your stack trace will lead you to a very small subset of code instead of a 1000-line file of code. When pushing updates to a particular module, say the comments system on a blog CMS, you won’t have to take the whole system down — only the parts that are being updated.
2. Test
Rule 2: Test. I'm guilty of not always writing tests for my code. All production code should have tests.
— Karan Goel (@karangoel) January 16, 2015Yes. I know. Testing. Blekhh!
Let me tell you why you just did that. Because we have been trained to treat testing as a different activity than making software. Even in school, you are taught how the C++ templates work, but not how they are tested. Online tutorials will teach you how to make a sick web server in Brainfuck, but they won’t tell you how to test it. And that is the problem.
Some people will tell you that you should write tests before you start writing the actual application logic.
I, on the other hand, don’t care when you write tests, as long as you write some tests. Don’t try to be a testing hero when you first start out; start simple. Test in a brute force way (eg. print(add(1, 1) == 2)) then move onto a testing framework for your language.
Here’s what will happen when you start testing your code — you’ll start to understand the complexity of your software. You’ll start to learn how to modularize your software into pieces that can be independently tested. So just by nailing testing, you will have followed two of the seven rules here. Power to you.
3. Continuous Integration
Rule 3: Use continuous integration. @travisci, @droneio and @jenkinsci all are great. They notify you as soon as you push broken code.
— Karan Goel (@karangoel) January 16, 2015After you write tests, you have to make sure they pass, and you have to make sure they pass in multiple environments (multiple versions of Python for example). You also need to test whenever any changes are made.
While you can do that manually from your command line, it’s more convenient, faster and cheaper to just use a continuous integration platform.
Thoughtworks has a beautiful page on CI. Here’s what you must know:
Continuous Integration (CI) is a development practice that requires > developers to integrate code into a shared repository several times a > day. Each check-in is then verified by an automated build, allowing > teams to detect problems early.
I use both TravisCI and Drone.io for my projects. Whenever I check in new code (or someone else does), the platforms build my code and run the tests.
4. Automate
Rule 4: Automate. Have 5 scripts that need to run to test & deploy? Add them in a single bash script. Reduce the steps. Save time.
— Karan Goel (@karangoel) January 16, 2015Bigger projects often have some tasks like bootstrapping code, or testing code in different ways, or for deploying to different servers, or for backing up parts of code.
I have seen people store txt files with commands, and copy paste when they need to. Do yourself a favor and learn bash scripting (and/or Python).
Here are some common tasks that you must automate using simple bash scripts:
-
Converting README.md to other formats (depending on what different distribution channels require)
-
Automated testing (including creating mock servers and/or data, deleting temp files, etc).
-
Stage code to dev server.
-
Deploy to production.
-
Automated dependency updating (be careful, you don’t always want to do this, especially when updates can break existing API).
5. Redundancy
Rule 5: Redundant version control: Don't rely on just Github. Use multiple synced off-site remotes and increase redundancy.
— Karan Goel (@karangoel) January 16, 2015This is the first thing you see when you go to git-scm.com (emphasis mine):
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Distributed version control. Distributed. That’s the keyword.
Pinch yourself if you host your code on Github, and Github only. Why? There’s a single point of failure. If Github goes down, or if you push corrupted files in the repo, your workflow will halt.
Ok. Now, signup for Bitbucket, and do this in your repo:
Now whenever you push to origin, your changes are pushed to both Github and Bitbucket.
You never know when shit will go wrong (because it can). It’s never a bad idea to maintain off-site backups of your code. You never know when there’s a disaster that affects just your city.
For reference, here’s what my code storage look like:
-
All code lives in “Codebase” folder in Dropbox. Automatic syncs on changes.
-
Almost all code lives on Github.
-
The most important code lives on 2 other private mirrors — one hosted by my school, and the other than I maintain on AWS.
The only way I am losing my code is if the whole world is wiped off.
6. Commits
Rule 6: Commits: Make small changes, commit and push often. Never push broken code. Use sensible commit messages.
— Karan Goel (@karangoel) January 16, 2015This will feel familiar. Look into your commit history, I bet you’ll find something similar to this:
“fixed issue with module”
ARE. YOU. SERIOUS.???
What does “fixed” mean? What “issue” was there? Which “module”?
A ton of us programmers treat version control systems as a means of backup, and not a means of maintaining history. History full of messages like these is useless unless all you want to do is retrieve files back.
A week after you check in changes with this commit message, you realized you need to revert something back because somewhere down the line a new bug was introduced. Now because your commit messages suck and have no descriptions, you’ll need to look at the changes. That is exactly what version control systems were made to prevent (other than emailing code).
If it’s too hard to write good commits, just follow this template:
-
Each commit should have a purpose. Is it fixing a bug, or adding a new feature, or removing an existing feature?
-
Only one change per commit. Commit when you solve issue #127, and only that issue.
-
Include issue number in the commit message.
-
Include a description of the change in commit description. This depends on the project contributing guidelines but usually you mention what was causing the bug, and how you fixed it, and how to test the change.
-
Write sensible commit message:
fixed cache being reset on every insert caused by missed access after write. fixes #341
Or…
added a new form in header to make it easier to collect leads. close > #3
And definitely not
remove stuff because why not.xoxo
7. Plan
Rule 7: Have a plan: Prepare for the worst case. What exactly will you do when something does go wrong? Document those steps in detail.
— Karan Goel (@karangoel) January 16, 2015You’ve been religiously following the other 6 rules and are a total boss in the software development. But your software is not invincible. Thinking otherwise would be naive.
Due to whatever or whoever’s mistake, shit will go down.
Have a plan ready for the worst case. What will you do when your traffic skyrockets? Where do you pull backups from when the system is down due to an unknown bug? Who would you call in the middle of the night when your server goes down?
Think this through. But don’t overthink it. Then automate steps that can be automated.
Now document it all. In detail. Make it so anyone acquiring your code also has the plan ready.
Not only will having a plan make you seem smarter, it will actually make you smarter.
End
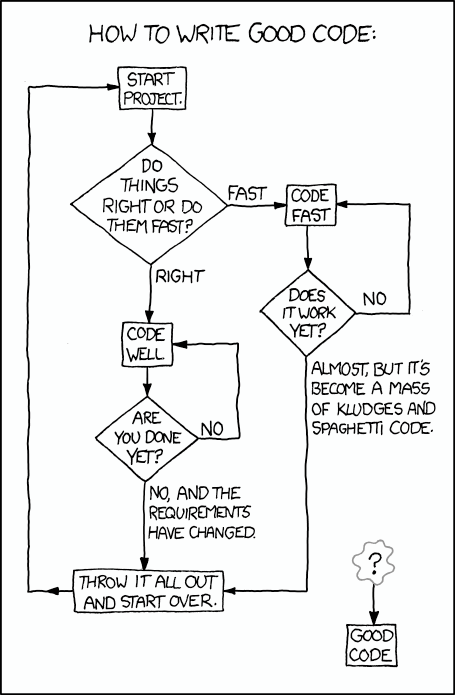 There’s always a relevant xkcd: http://xkcd.com/844/
There’s always a relevant xkcd: http://xkcd.com/844/
These are just the rules that I believe define good software. If you still are not convinced to follow them, answer these two questions:
-
Would you expect someone new to join your team and be able to understand existing code easily?
-
When refactoring the code, is it easy and quick?
If you said “no” to any of the questions, re-read this post. Bookmark it. Share it with your team. You’ll be doing them a favor.
These rules may seem obvious at first. And let me tell you, they are. Bad code gets written all the time, and eventually that bad code is killed.
Remember, your software is your legacy. It is up to you to decide how long that legacy lives for.
Happy programming.
Thanks to Katie McCorkell, Stefan Dierauf, Iheanyi Ekechukwu, Mohammad Adib and Skyler Kidd for reading drafts of this.